

We can’t send you updates from Justia Onward without your email.
Unsubscribe at any time.
Search engines have long tried to extrapolate meaning from the content of your web pages. While they have gotten pretty good at it, it is easier for them if you can be explicit in the meaning of your content. The best way to do that is by using structured data. In this post we explain what Structured Data is, and how you can implement it in your content.
In the early days of the web, search engines were little more than a word search. Typing in “pineapple” would give you every page on the internet that talked about pineapples, with some priority given to the sites that talk about pineapple more than others. Later Google came on the scene and tried to create a more robust ranking algorithm to distinguish higher quality sites about pineapples, not just pages that replace every other word with the word “pineapple.” As an aside, in the early search engines this article would probably rank really well for “pineapple” even though it has absolutely nothing to do with pineapples, just because I’ve used the word “pineapple” eight times in this opening paragraph. Today’s Google on the other hand would not rank me very well for that word.
As search engines continue to get better and better over the last 2 decades, people use search more and more to simply answer life’s questions. If you type into your favorite search engine “How old is Steve Martin?” odds are the search engine will actually answer your question, rather than just give you a list of links. They can do this because the search engine spiders are no longer simply indexing a list of words that are on a web page, but trying to break down those words into actual facts, for which they can then extrapolate an actual answer.
If you ask Google how old Steve Martin is, Google will take his birthday, which is a fact they’ve extracted from somewhere, and the current date and return to you that he is (as of the time of this writing) 71 years old. Now Google’s robots get a lot of this information by passing the phrases on the web pages they index through a technology known as Natural Language Processing in order to take sentences and break them down into facts. Not only do they do this to the content of the pages, but they actually do this to the strings you type into the search box to turn your question into something a computer can actually understand.
Natural Language Processing is getting pretty good these days, but it isn’t perfect. Often times it will see a phrase and incorrectly interpret it as something else. But why should the robots have to work so hard to understand your content in the first place?.
What Is Structured Data?
One thing that all the search engines can agree on is that it would be best if the content writers could actually tell the robots the facts in a way that the computers can easily understand. A consortium of companies that work in search (Google, Microsoft, Yahoo, and Yandex), have banded together to sponsor an effort called schema.org which aims to create a standard vocabulary that webmasters can use to mark up their data in a way that both people and computers can easily understand.
Consider the following paragraph
John Glover Roberts, Jr. is the Chief Justice of the United States Supreme Court. He was born on the to Rosemary and John Glover Roberts, Sr. (-) in Buffalo, New York. He married Jane Marie Sullivan in 1996 and they have 2 children, Josephine and Jack.
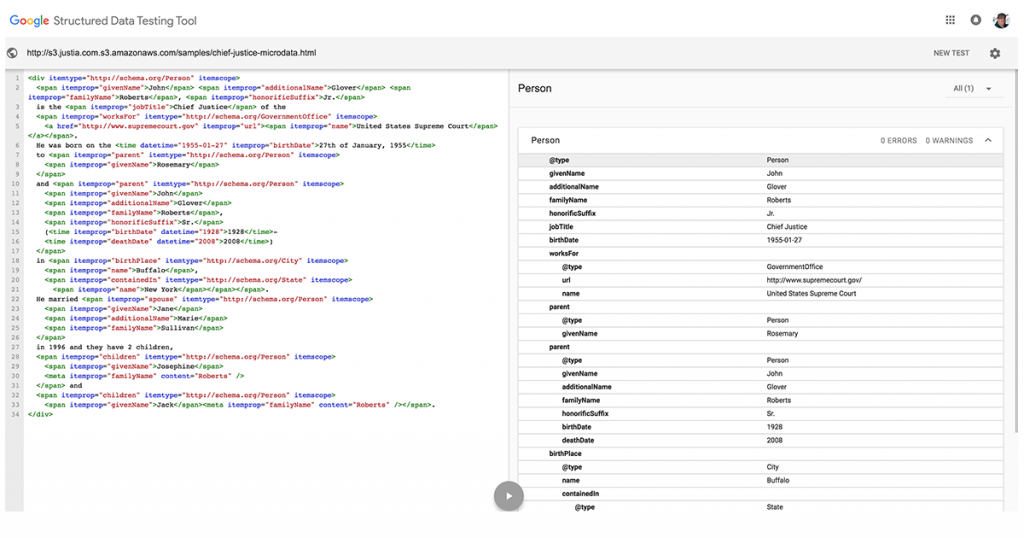
There’s quite a lot of information packed into those 3 sentences, and in fact if you pass this page through Google’s Structured Data Testing Tool you’ll see that paragraph is transformed into a plethora of easy to parse data, taking every piece of information in those sentences and making it readable to machines. All of the markup to extract that data is actually in the paragraph above, yet it is invisible to the reader. The reader simply sees a paragraph, but Googlebot can easily extrapolate that data into useful information that could feed their knowledge graph to give actual answers.
Let’s take a look at the markup for this paragraph both before and after the schema.org markup was added.
<div>
John Glover Roberts, Jr. is the Chief Justice of the
<a href="http://www.supremecourt.gov">United States Supreme Court</a>.
He was born on the 27th of January, 1955
to Rosemary and John Glover Roberts, Sr. (1928 - 2008)
in Buffalo, New York.
He married Jane Marie Sullivan in 1996 and they have 2 children,
Josephine and Jack.
</div>
As you can see, all of the details are there, and a human eye can read these sentences and understand that the name of Chief Justice Roberts’ son is Jack. But if this page was what Google was basing their knowledge about him on, someone asking Google how old Chief Justice Roberts is would not be given this page, as there is no point in that paragraph that says how old he is.
By adding schema.org markup to this paragraph, you can mark this data up into a ton of metadata
<div itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">John</span> <span itemprop="additionalName">Glover</span> <span itemprop="familyName">Roberts</span>, <span itemprop="honorificSuffix">Jr.</span>
is the <span itemprop="jobTitle">Chief Justice</span> of the
<span itemprop="worksFor" itemtype="http://schema.org/GovernmentOffice" itemscope>
<a href="http://www.supremecourt.gov" itemprop="url"><span itemprop="name">United States Supreme Court</span></a>
</span>.
He was born on the <time datetime="1955-01-27" itemprop="birthDate">27th of January, 1955</time>
to <span itemprop="parent" itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">Rosemary</span>
</span>
and <span itemprop="parent" itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">John</span>
<span itemprop="additionalName">Glover</span>
<span itemprop="familyName">Roberts</span>,
<span itemprop="honorificSuffix">Sr.</span>
(<time itemprop="birthDate" datetime="1928">1928</time>-
<time itemprop="deathDate" datetime="2008">2008</time>)
</span>
in <span itemprop="birthPlace" itemtype="http://schema.org/City" itemscope>
<span itemprop="name">Buffalo</span>,
<span itemprop="containedIn" itemtype="http://schema.org/State" itemscope>
<span itemprop="name">New York</span>
</span>
</span>.
He married <span itemprop="spouse" itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">Jane</span>
<span itemprop="additionalName">Marie</span>
<span itemprop="familyName">Sullivan</span>
</span>
in 1996 and they have 2 children,
<span itemprop="children" itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">Josephine</span>
<meta itemprop="familyName" content="Roberts" />
</span> and
<span itemprop="children" itemtype="http://schema.org/Person" itemscope>
<span itemprop="givenName">Jack</span>
<meta itemprop="familyName" content="Roberts" />
</span>.
</div>
This may look like a lot more code, and someone trying to read the html of the page may have a harder time reading what this paragraph says, but to a machine this bit of extra code is gold. When a browser interprets the two versions, the user sees the same thing in each instance, but when the second one is passed through the structured data testing tool, Google is able to take this content and determine all sorts of information about the Chief Justice of the Supreme Court.
While going through this amount of work for every single page you want to create may seem excessive (and if you were manually writing it all, it would be) but more likely than not, your website is created by some sort of Content Management System (CMS), a way of storing the content of your site in a database, and building the html from that database. If your database is structured well enough, you can simply include the structured data output into your templating system.
More on Structured Data
The paragraph example I gave above is structured using the schema.org Person type. If you want a larger example of the Person type, check out profile pages on the Justia Lawyer Directory. These pages are also marked up with the schema.org/Person type, making it easier for search engines to identify the various pieces of information on the page. You can see how Googlebot sees this content, by passing a page through the structured data testing tool. Here is an example using our CEO, Tim Stanley’s profile.
There is a lot more to be said about structured data and how it affects your SEO efforts, including information about how this structured data can change the way your site is displayed in Google search results pages, but we’ll leave this here for now. In today’s ever competitive SEO landscape, it is important that the company you choose to create and maintain your website understands and implements structured data on your site.
As Google and other search engines advance further from mere indexing of words to learning of information, be sure that you or your webmaster stays abreast of the latest changes to keep you at the fore of SEO practices. If you are concerned that your law firm website or blog does not use these modern SEO techniques, including structured data, responsive design and more, please contact us to find out how Justia can bring your website into the 21st century.







